
Your data science team achieves a 95% accuracy model. But six months and half a million later, the model still isn't in production.
If this sounds familiar, you're not alone.
Here's what most people don't talk about: As a data engineer working on ML projects across multiple teams, I've learned the real work isn't building models, it's managing data. Getting access takes weeks. Understanding different formats takes longer. Then comes the real challenge: figuring out what needs cleaning, how to clean it, and building feedback loops when transformations fail. Monitoring never stops, and improvements never end. It's an ongoing battle, not a one-time fix.
This article examines ML project failures through a data engineering lens, because that's where most projects typically fail, not in model architecture, but in the data foundation beneath it. Whether you are a data leader, engineer, or executive, understanding the crucial role of solid data foundations will drive your AI success.
And the numbers back this up. Poor data quality costs organisations $12.9 million per year, according to Gartner, and can reach $15M in sectors like supply chains. MIT's research shows most generative AI pilots do not deliver value, while RAND found a high rate of AI project failures—much higher than traditional IT projects.
The culprit? Data chaos, not algorithms. While teams debate which transformer architecture to use, their data foundation is falling apart. Data scientists spend 40-60% of their time cleaning and wrangling data instead of building models.
In this article, we'll first explore why projects fail. Then, we'll examine Zillow's $881M lesson in what not to do, followed by how companies like Wayfair reduced deployment time from one month to one hour using MLOps on Vertex AI. Next, I'll show you why these approaches are now accessible to teams of all sizes—not just tech giants. Finally, I'll provide a practical, step-by-step approach for data leaders to start improving their MLOps maturity. This roadmap will help you set clear expectations for effectively integrating these practices into your organisation.
The Real Cost of Data Chaos
What Failure Actually Looks Like
Not every ML failure looks the same. There's a spectrum:
- Complete failure: The model never makes it to production (40-50% of projects)
- Partial failure: It deploys but doesn't deliver ROI (30-35%)
- Technical success, business failure: It works technically but solves the wrong problem (15-20%)
Recent data shows the problem is worsening: MIT reports that most generative AI pilots fail, and the percentage of businesses abandoning AI initiatives is rapidly rising.
Beyond Financials: The Ethical and Environmental Costs
The "hidden costs" of data chaos extend far beyond financial waste and lost productivity. Two of the most critical and fastest-growing concerns are ethical blind spots and environmental drains.
The Ethical Blind Spot (Bias in Chaos): Data chaos isn't just messy; it's a significant ethical liability. When training data is a "multi-source nightmare" pulled from scattered systems without unified governance, you have no way to audit it for fairness or representation. This is how biased models are born, amplifying historical biases hidden in that chaotic data. This isn't just a social issue; it's a governance failure.
The Environmental Drain (Compute Waste): The "Infrastructure Waste" and "Model Waste" we identified have a real-world carbon footprint. Every failed experiment, redundant training run, and over-provisioned cluster is wasted compute, consuming massive amounts of energy. When data scientists spend "40-60% of their time" on data wrangling, they are often running compute-heavy tasks on unoptimized data, multiplying this environmental drain.
A proper MLOps strategy, therefore, isn't just about saving money. It's about establishing the governance needed to build fair and accountable AI, and the efficiency needed to do so sustainably. Your Data Control Plane is the foundation for solving all three—financial, ethical, and environmental.
Where the Money Goes
- Lost Productivity: Data scientists spending 60-80% of time on data wrangling
- Infrastructure Waste: Over-provisioned resources, duplicate training runs
- Model Waste: Training on stale data, failed experiments
- Compliance Costs: Ensuring data privacy, security, and accessibility
- Opportunity Cost: Missing out on AI-driven innovation
But here's what changes with proper MLOps:
| What You Measure | Without MLOps | With MLOps | Improvement |
|---|---|---|---|
| Failure Rate | 80-95% | Under 20% | 75% reduction |
| Data Prep Time | 40-60% of project | 10-20%* | 50-75% faster |
| Time to Production | 6-12 months | 2-8 weeks | 10x acceleration |
*Based on automation reducing 50-75% of manual data wrangling work through Feature Store and pipeline automation
At QCon SF 2024, Grammarly's engineering team shared their analysis of why ML projects fail. Their conclusion? Data quality is the number one issue. As they put it: "Garbage in, garbage out."
The Five Patterns That Kill ML Projects
Pattern #1: The Multi-Source Data Nightmare
Your training data lives in AWS S3. Production logs are in GCP. Customer data sits in an Azure database. Each needs different credentials, has different networking requirements, and uses a different API.
This isn't theoretical. In my experience, this is where most time disappears. You spend 2-3 weeks per project just setting up data access before any actual modeling begins. Security vulnerabilities from credential sprawl compound the productivity losses.
This connects to my recent article about orchestration architecture decisions. Proper orchestration helps, but getting your data under control is the first step.
Pattern #2: The Notebook-to-Production Gap
Jupyter notebooks are perfect for experimentation. But getting from notebook to production? That's where projects die.
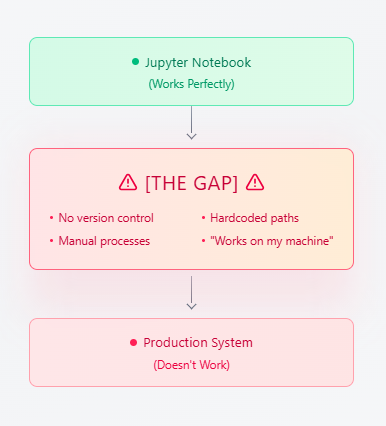
RAND's 2024 analysis found that teams often misunderstand which problems to solve, organisations lack the right data, and infrastructure needs are underestimated. As a result, it can take 3-6 months to get a working model into production, with most of the effort spent on engineering instead of ML.
But things are changing. Vertex AI makes this transition smooth instead of difficult. Managed notebooks automatically track experiments, and with one click, you can turn your notebook into a production pipeline. You no longer need to be an expert in distributed systems, as YAML files and automation handle the complexity.
Pattern #3: The Experiment Amnesia Problem
Three months ago, your team trained a model that performed well. Now you need to reproduce it. Nobody remembers which hyperparameters were used, which data version, or which preprocessing steps were applied.
This organisational memory loss is expensive. NewVantage's 2024 survey found that 92.7% of executives identify data as the biggest barrier to AI success. However, here's the kicker: only 48% of data scientists consistently measure their performance. Teams track technical metrics, such as AUC, but often overlook business KPIs, like ROI.
Why this matters for enterprises: Beyond wasted compute and lost knowledge, this lack of tracking creates serious compliance and governance issues. Regulated industries like finance, healthcare, and government require complete audit trails regarding which data was used, when, by whom, and what model version was deployed. Without proper version control and lineage tracking, you can't pass audits, demonstrate compliance with regulations such as GDPR or HIPAA, or explain to regulators how a model made a specific decision. Consider a compliance scenario where an auditor requests the exact data path for prediction #123. Without a clear lineage, providing a detailed answer becomes a challenge, turning what might seem like a tech problem into a significant business risk. Proper data lineage can transform governance from a mere checkbox requirement into a crucial safeguard.
The result? Wasted compute, lost knowledge, failed audits, and inability to improve models systematically.
Pattern #4: Zillow's $881M Lesson in Data Quality Blindness
In 2021, Zillow shut down its iBuying business (Zillow Offers), writing off $881 million in losses—including a $540M+ write-down from their failed home-buying algorithm. The company had world-class data scientists, massive datasets, and years of experience. What went wrong?
The breakdown:
- Their Zestimate algorithm made inaccurate home valuations
- Models couldn't handle rapid post-pandemic market volatility
- Training data became stale in unprecedented conditions
- No effective monitoring detected when predictions drifted from reality
- Result: Zillow overpaid for homes they couldn't resell profitably
The lesson isn't that ML is risky. Even sophisticated teams fail catastrophically without proper data quality management and monitoring. This pattern repeats across industries: Amazon's biased hiring algorithm, healthcare AI misdiagnoses, facial recognition errors, all stem from the same root cause: inadequate data governance.
Pattern #5: The "Works on My Machine" Production Gap
Development environments don't match production. Manual deployment processes create bottlenecks. Models degrade silently in production with no alerts.
The 2024 State of MLOps survey identified the top challenges: tracking experiments (62%), model decay (61%), and tool complexity (60%). Without proper monitoring, you only discover failures when customers complain.
Why Traditional Solutions Don't Work
The "Buy More Tools" Trap
Organisations think they can solve data chaos by purchasing more tools. The result? Ten disconnected systems requiring custom glue code and specialist knowledge for each one.
Tool sprawl creates more complexity than capability. Each additional solution introduces new integration challenges without addressing the underlying governance gaps. Takeaway: Purchasing more tools does not fix foundational data issues.
The "Hire More People" Illusion
Building custom MLOps infrastructure sounds appealing until you calculate the cost. You need ML engineers, DevOps experts, data engineers, platform engineers, and ongoing maintenance teams. Total cost of ownership? Often exceeds $2M annually, which is a barrier for all but the largest companies.
What's Actually Missing
The fundamental issue isn't lack of tools or people. It's the absence of a unified data control plane—a system that brings order to data chaos through:
- Centralised access control across all data sources
- Automated governance with version tracking and lineage
- Unified interfaces that abstract away complexity
- Built-in monitoring that catches problems before production impact
The Data Control Plane: Your Path Out of Chaos
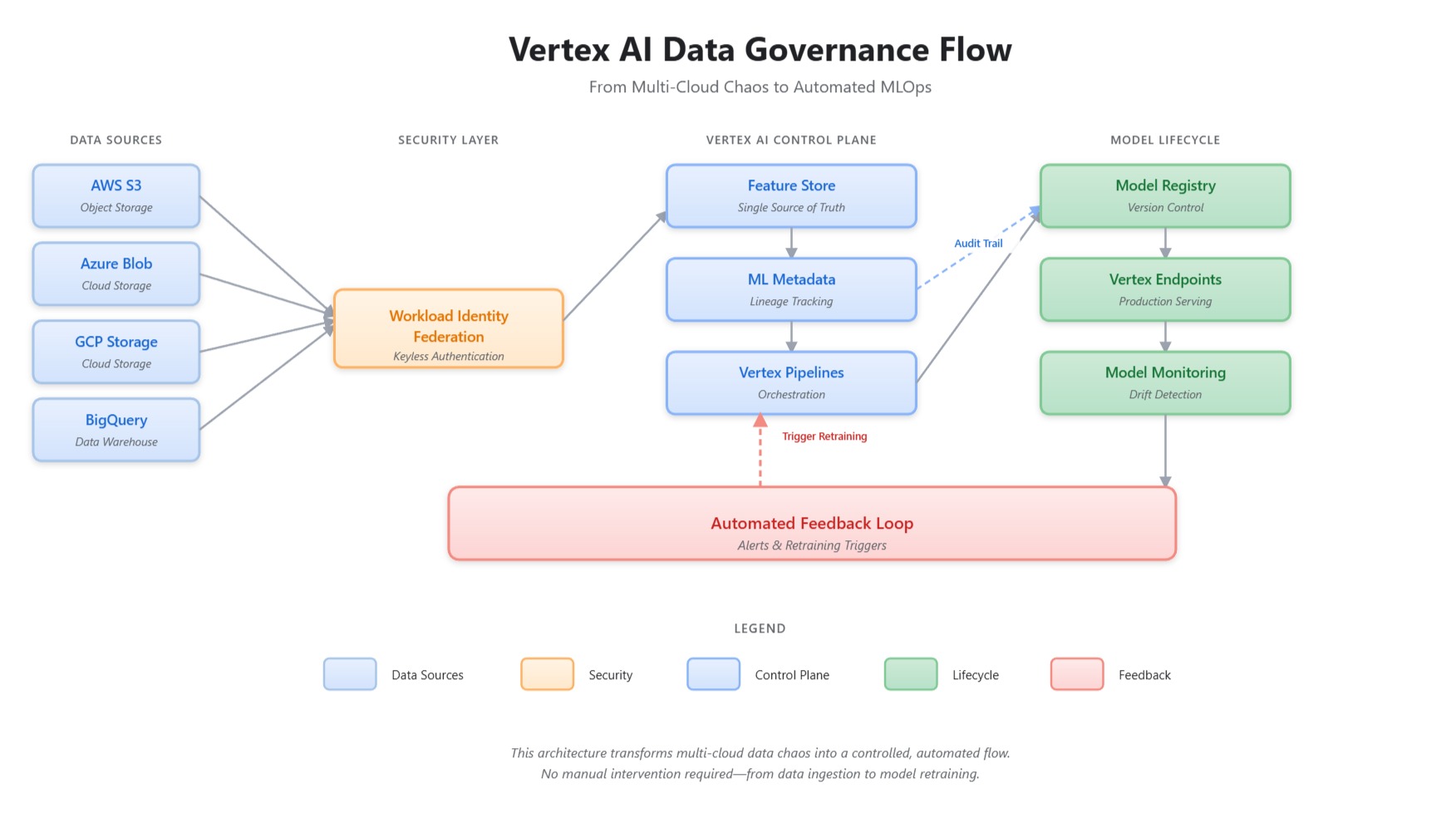
What Is a Data Control Plane?
Think of it as air traffic control for your ML data. Instead of each team managing their own access, authentication, and governance, a data control plane provides:
1. Single Point of Access
- One interface to all data sources (AWS, Azure, GCP, on-prem)
- Consistent authentication via Workload Identity Federation
- Automatic credential management with zero static keys
2. Built-In Governance
- Automatic lineage tracking from raw data to deployed models
- Version control for datasets, features, and models
- Compliance-ready audit trails for regulated industries
3. Production Readiness
- Automated pipelines from experiment to production
- Continuous monitoring for data drift and model decay
- Rollback capabilities when issues arise
How Vertex AI Implements the Control Plane
Google Cloud's Vertex AI provides this control plane without requiring you to build it from scratch. Here's what it includes:
Feature Store: Your Single Source of Truth
from google.cloud import aiplatform
# Initialise with your project
aiplatform.init(project="your-project-id", location="us-central1")
# Create a feature store - your central data repository
feature_store = aiplatform.Featurestore.create(
featurestore_id="enterprise_ml_features",
online_serving_config=aiplatform.featurestore.FeaturestoreOnlineServingConfig(
fixed_node_count=1
),
labels={"team": "ml-platform", "env": "production"}
)
# Define entity types (e.g., customers, products, transactions)
customer_entity = feature_store.create_entity_type(
entity_type_id="customers",
description="Customer behavioural and demographic features"
)
# Register features with automatic versioning and lineage
customer_features = [
aiplatform.Feature(
value_type="INT64",
description="Total lifetime purchases"
),
aiplatform.Feature(
value_type="DOUBLE",
description="Average order value"
),
aiplatform.Feature(
value_type="STRING",
description="Customer segment classification"
)
]
# Ingest data from multiple sources with automated governance
customer_entity.batch_create_features(
feature_configs=customer_features
)
# Your data is now centralised, versioned, and ready for production
print(f"Feature Store created: {feature_store.resource_name}")
print(f"Features registered with automatic lineage tracking")What This Code Actually Does:
- Creates a production-ready feature store with automated scaling
- Establishes entity types that map to your business domain
- Registers features with automatic version tracking
- Enables lineage tracking from raw data sources to deployed models
- Provides both online (low-latency serving) and offline (batch training) access
ML Metadata: Complete Audit Trails
Every experiment, dataset version, and model gets tracked automatically:
# Vertex AI automatically tracks:
# - What data was used (data lineage)
# - Which code version trained the model (code lineage)
# - What hyperparameters were chosen (experiment tracking)
# - How the model performed (evaluation metrics)
# - When it was deployed (deployment history)
# Query experiment history
experiments = aiplatform.Experiment.list()
for exp in experiments:
print(f"Experiment: {exp.name}")
print(f"Runs: {len(exp.get_runs())}")
print(f"Best accuracy: {exp.get_best_run('accuracy').metrics['accuracy']}")Vertex Pipelines: Automated Orchestration
Turn your notebook into a production pipeline:
from kfp import dsl
from google.cloud import aiplatform
@dsl.pipeline(
name="production-ml-pipeline",
description="End-to-end ML with automated governance"
)
def ml_pipeline(
project: str,
data_source: str,
model_display_name: str
):
# Data ingestion with automatic lineage
data_op = dsl.ContainerOp(
name="ingest-data",
image="gcr.io/your-project/data-ingestion:latest"
)
# Feature engineering tracked in Feature Store
feature_op = dsl.ContainerOp(
name="create-features",
image="gcr.io/your-project/feature-eng:latest"
).after(data_op)
# Model training with experiment tracking
train_op = dsl.ContainerOp(
name="train-model",
image="gcr.io/your-project/training:latest"
).after(feature_op)
# Automatic deployment if metrics pass threshold
deploy_op = dsl.ContainerOp(
name="deploy-model",
image="gcr.io/your-project/deployment:latest"
).after(train_op)
# Compile and run
aiplatform.PipelineJob(
display_name="production-ml",
template_path="pipeline.json",
pipeline_root="gs://your-bucket/pipeline-root"
).run()Real-World Success: Wayfair's Transformation
Wayfair faced the same challenges many enterprises do: multiple data sources, slow deployments, and scaling issues. Here's how Vertex AI's data control plane changed their operations:
Before MLOps:
- Deployment time: 1 month per model
- Manual feature engineering for each use case
- Limited ability to experiment at scale
- Data scattered across multiple systems
After Vertex AI Implementation:
- Deployment time: 1 hour (96% reduction)
- Centralised Feature Store serving 100+ models
- Real-time predictions at massive scale
- Unified data access with automated governance
2025 Expansion: In their latest integration with Google Cloud, Wayfair leveraged Gemini on Vertex AI to enrich their product catalogs—automatically generating high-quality product descriptions and metadata. This further reduced manual data work, enabling their ML teams to focus on model innovation rather than data preparation. The combination of automated feature engineering and generative AI for data enrichment created a complete MLOps ecosystem.
The key insight? Wayfair didn't need to hire a 50-person MLOps team. Vertex AI's managed platform provided the data control plane they needed, allowing their existing ML engineers to focus on business problems instead of infrastructure.
Building Your MLOps Maturity
Most organisations aren't ready to jump straight to full MLOps. Here's the practical path forward, regardless of your current state:
Level 0: Manual Process (Where Most Teams Start)
What it looks like:
- Jupyter notebooks without version control
- Manual feature engineering for each experiment
- Manual model deployment requiring DevOps tickets
- No monitoring; learning about failures from users
Time to production: 6-12 months (if ever)
Failure rate: 80-95%
Level 1: ML Pipeline Automation (Your First Win)
What you add:
- Automated training pipelines using Vertex AI
- Feature Store for reusable features
- Experiment tracking with ML Metadata
- Continuous training on new data
Implementation time: 2-3 weeks for first pipeline
Result: Training becomes repeatable and tracked
Quick start code:
# Convert your notebook to a pipeline in under 100 lines
from google.cloud import aiplatform
from kfp import dsl
# Define your pipeline
@dsl.pipeline(name="first-ml-pipeline")
def simple_pipeline():
# Your existing training code, now automated
training_job = aiplatform.CustomTrainingJob(
display_name="automated-training",
script_path="train.py",
container_uri="gcr.io/cloud-aiplatform/training/tf-cpu.2-11:latest",
requirements=["scikit-learn==1.3.0", "pandas==2.0.3"]
)
model = training_job.run(
dataset=aiplatform.TabularDataset("bigquery://project.dataset.table"),
model_display_name="my-first-automated-model",
training_fraction_split=0.8,
validation_fraction_split=0.1,
test_fraction_split=0.1
)
# Deploy automatically if validation metrics pass
endpoint = model.deploy(
machine_type="n1-standard-4",
min_replica_count=1,
max_replica_count=10
)
# Run it
aiplatform.PipelineJob(
display_name="my-pipeline",
pipeline_root="gs://your-bucket/pipeline-root"
).run()Immediate benefits:
- Reproducible experiments
- Version-controlled models
- 50% reduction in data prep time
Level 2: Automated Deployment (Production Ready)
What you add:
- Automated model deployment with Vertex Endpoints
- Model monitoring for drift detection
- A/B testing capabilities
- Automated rollback on performance degradation
Implementation time: 4-6 weeks building on Level 1
Result: One-click production deployments with safety nets
Level 3: Full MLOps (Google-Scale Reliability)
What you add:
- Continuous integration/deployment (CI/CD) for ML
- Automated retraining triggers
- Feature monitoring and alerting
- Complete observability across the lifecycle
Implementation time: 3-6 months with proper platform
Result: Self-healing ML systems with 75% reduction in failures
Your Practical Starting Point
Don't try to jump to Level 3 overnight. Here's what to do this week:
Day 1-2: Audit Your Current State
- How many data sources do you access?
- How long does it take to get data for training?
- Where are credentials stored? (this is usually scary)
- How many hours per week go to data wrangling?
Day 3-5: Set Up Your First Feature Store
- Create a Vertex AI Feature Store (1 hour)
- Migrate one frequently-used dataset (2-3 hours)
- Document the time saved on next experiment
Week 2: Automate One Pipeline
- Pick your most frequently retrained model
- Convert the notebook to a Vertex Pipeline
- Set up automated training on new data arrival
Week 3-4: Add Monitoring
- Deploy your model to a Vertex Endpoint
- Configure monitoring for prediction drift
- Set up alerts for performance degradation
Result after 4 weeks: You've established the foundation of your data control plane. One automated pipeline that's monitored, governed, and production-ready. Now replicate this pattern for your other models.
Why Vertex AI Makes This Accessible
Five years ago, building this infrastructure required dedicated MLOps teams and millions in investment. Today, Vertex AI provides:
1. Managed Infrastructure
- No need to build and maintain feature stores
- No pipeline orchestration complexity
- No custom monitoring systems to debug
- Cost: Pay only for what you use, not a 50-person team
2. Integrated Governance
- Automatic lineage tracking for compliance
- Built-in experiment tracking and versioning
- Enterprise security with IAM and VPC controls
- Benefit: Pass audits without custom development
3. Production-Grade Reliability
- Google's infrastructure handles scale
- Automatic failover and redundancy
- SLA-backed uptime guarantees
- Result: Focus on models, not infrastructure
4. Team Efficiency
- Your existing ML engineers can use it immediately
- Python SDKs feel natural to data scientists
- Notebooks integrate seamlessly
- Outcome: Weeks to value, not years
This is what I call MLOps democratisation: capabilities that once needed a huge investment are now available to teams of any size.
The Path Forward
Data chaos isn't a technical problem you solve once. It's an ongoing challenge that requires proper infrastructure and governance. The choice isn't building everything yourself or doing nothing; it's about leveraging existing platforms to establish control.
The transformation is proven:
- Wayfair: 1 month → 1 hour deployment time, plus 2025 Gemini integration for data enrichment
- Industry leaders: 75% reduction in failure rates
- Teams of all sizes: 10x faster time to production
Your path forward:
- Acknowledge the problem: Data chaos is costing you more than any model improvement could gain
- Establish your data control plane: Start with one component of MLOps
- Leverage existing platforms: Vertex AI provides the foundation without the $2M+ build cost
- Start this week: Pick your biggest pain point and address it
The democratisation of MLOps means you don't need Google-scale resources to achieve Google-scale reliability. Smaller organisations can now adopt these practices to unlock AI value and scale operations efficiently.
Try it yourself:
Start with Google Cloud's Vertex AI free tier and see how fast you can get a Feature Store running. In my experience, it takes about an hour to set up, which is exactly how long Wayfair now takes to deploy a complete production model.
Found this helpful? Share it with a colleague who is dealing with data chaos. Tag them in the comments. I'd love to hear about your experiences.
Also published on Medium - Join the discussion in the comments!